Video presentation

The quality of the parts' description heavily influences the part segmentation performance of methods based on vision-language models. For instance, the performance of PointCLIPv2 (left), deteriorates rapidly when replacing the default textual prompt with e.g., a GPT-generated description, the template "This is a depth image of an airplane's (part)", or simply using part names. In contrast, our pipeline (center) produces more accurate segmentations by disentangling part decomposition from part classification. The improvement is evident when utilising the same CLIP visual features as PointCLIPv2 (top) and further increases when using DINOv2 features (bottom), the default choice of COPS. COPS generates more uniform segments with sharper boundaries, resulting in higher segmentation quality.
Abstract
Supervised 3D part segmentation models are tailored for a fixed set of objects and parts, limiting their transferability to open-set, real-world scenarios. Recent works have explored vision-language models (VLMs) as a promising alternative, using multi-view rendering and textual prompting to identify object parts.
However, naively applying VLMs in this context introduces several drawbacks, such as the need for meticulous prompt engineering, and fails to leverage the 3D geometric structure of objects. To address these limitations, we propose COPS, a COmprehensive model for Parts Segmentation that blends the semantics extracted from visual concepts and 3D geometry to effectively identify object parts. COPS renders a point cloud from multiple viewpoints, extracts 2D features, projects them back to 3D, and uses a novel geometric-aware feature aggregation procedure to ensure spatial and semantic consistency. Finally, it clusters points into parts and labels them.
We demonstrate that COPS is efficient, scalable, and achieves zero-shot state-of-the-art performance across five datasets, covering synthetic and real-world data, texture-less and coloured objects, as well as rigid and non-rigid shapes.
Method
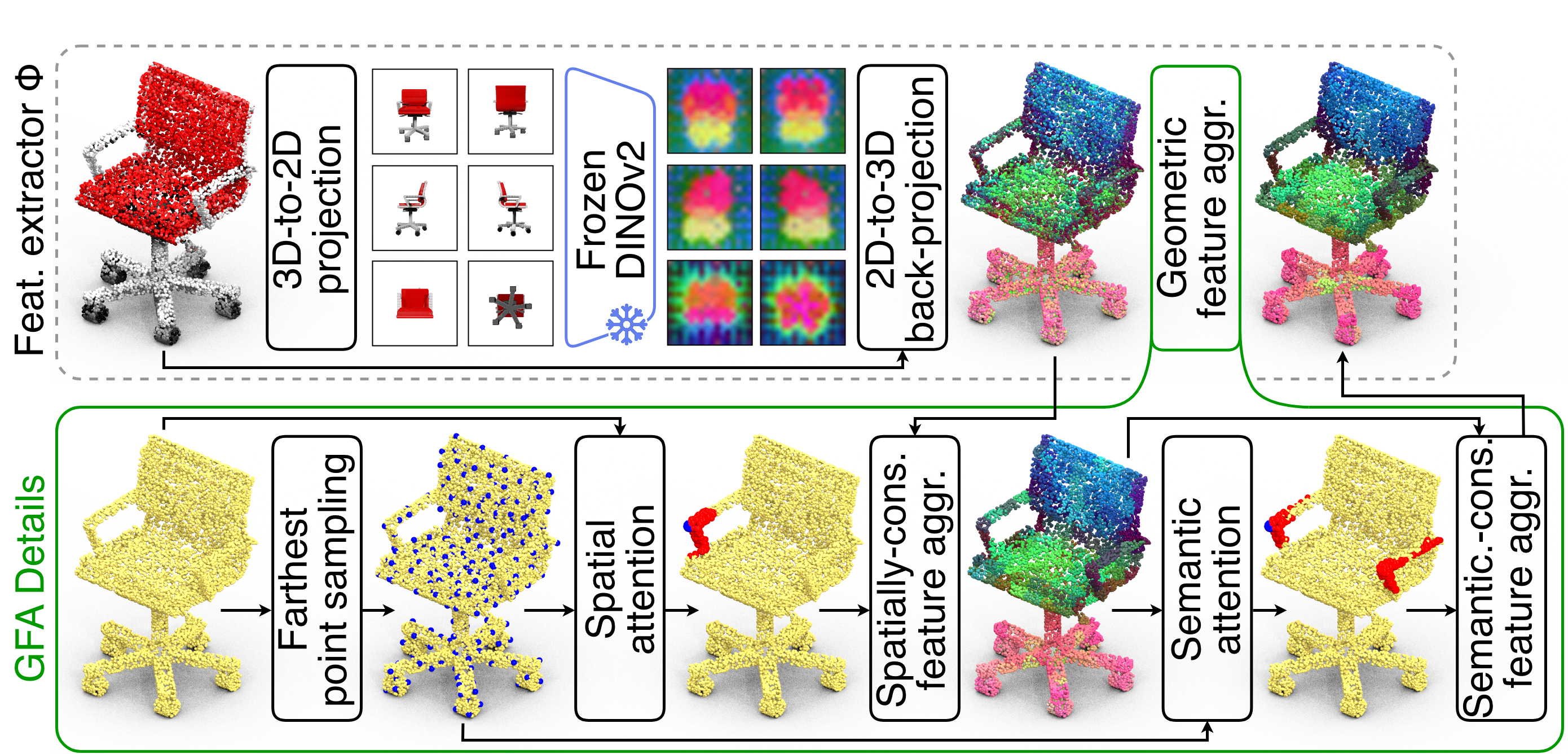
Overview of COPS's feature extractor. \(\Phi\) (top) extracts point-level features by (i) rendering multiple views of the object, (ii) processing them with DINOv2, (iii) lifting them in 3D.
The Geometric Feature Aggregation module (GFA, bottom) further refines these features by extracting superpoints (blue points in the second row) and their neighbouring points (red points in the second row) to obtain spatially consistent centroids. These centroids are used to perform spatial- and semantic-consistent feature aggregation, ensuring that the features are both locally consistent and similar across large distances when describing the same part (e.g. the armrest).
COPS performs feature extraction from 3D point clouds using DINOv2, which has been developed for image processing tasks and trained on unrelated web-scale data. Following common practice in the literature, we address the dimensionality gap by projecting 3D objects onto a collection of 2D images rendered from various viewpoints.
2D images are input into a pre-trained frozen DINOv2 base model to generate patch-level feature maps, which are then upsampled via bicubic interpolations to match the original rendering size. Pixel-level features are mapped back to 3D using correspondences between 2D pixels and 3D points computed by the rendering tool. Features from multiple viewpoints belonging to the same part of the 3D shape are clustered using a geometrically informed fusion mechanism to create a cohesive representation. These versatile 3D features can be applied to various point-level tasks related to 3D object understanding without additional training. We then perform zero-shot 3D point cloud part segmentation, by leveraging CLIP's predictions to align the clustered parts with semantic labels.
How COPS processes the input

Detailed visualisation of the steps required by COPS. From left to right:
- input point cloud,
- intermediate features obtained by 3D-lifting DINOv2 features,
- final features obtained with GFA,
- part decomposition obtained via feature clustering (colours are not informative because cluster labels are not semantic),
- PointCLIPv2 predictions,
- COPS predictions,
- and ground-truth segmentation.
Qualitative results
ShapeNetPart
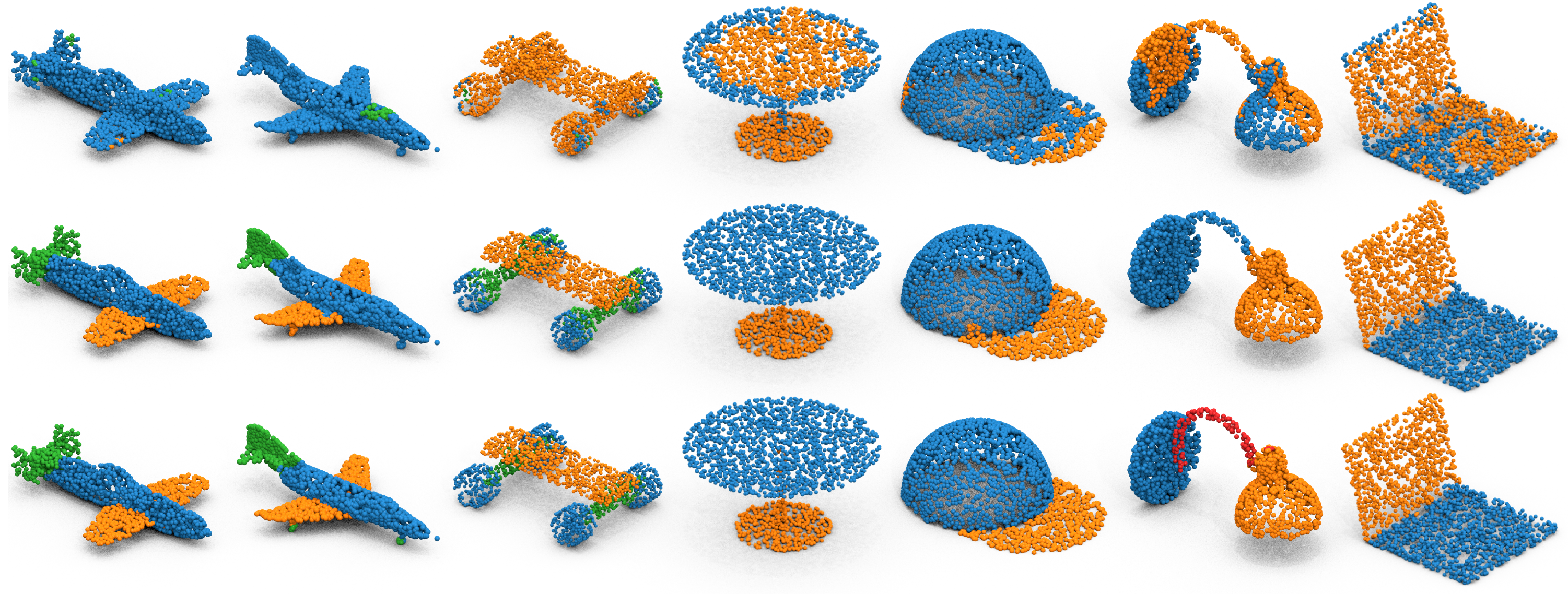
ScanObjectNN

FAUST

BibTeX
@article{garosi2025cops,
author = {Garosi, Marco and Tedoldi, Riccardo and Boscaini, Davide and Mancini, Massimiliano and Sebe, Nicu and Poiesi, Fabio},
title = {3D Part Segmentation via Geometric Aggregation of 2D Visual Features},
journal = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2025},
}